Nimbus Tech Stack (2019)
Nimbus (https://nimbusforwork.com) is an interesting company because we are operating in a very non-tech industry (cleaning). This has made it easy to be disruptive, however it also presents some unique difficulties for the products. Namely, cleaners are not very tech-savvy. Because of the lack of tech sophistication, we made a decision to be very deliberate before presenting changes and new features to our cleaners.
Surprisingly, without the "next feature fallacy" mentality we have been able to push out more products with less people. The mentality has instead morphed into "slow is smooth, smooth is fast". Our current tech team consists of one full timer (me) and one intern (working two days per week) who is in his second year at university.
Products
We did a lot of prototyping at the start of Nimbus, mostly quick and dirty web products and also a surpisingly successful Telegram chatbot. Now we have arrived at three relatively stable products - two mobile apps and a web interface.
Our mobile apps:
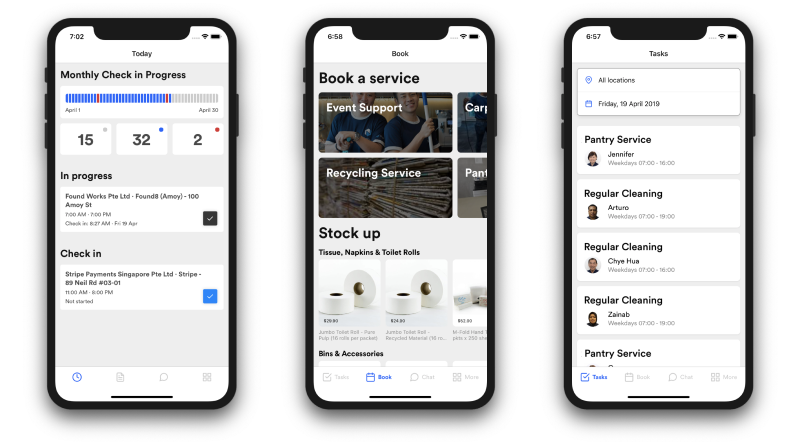 Crew app on the left, Customer App in the center and right
Crew app on the left, Customer App in the center and right
Crew App
An app for our crew to check in & out of their shifts, see their payslips, apply for leave, chat to their colleagues, and track attendance bonuses. It's also for our "on the ground" managers to monitor the staff from anywhere and make quick changes whenever there are problems.
Customer App
An app that allows our customers to see when cleaners, temp staff, and contractors are arriving and leaving, book new services (ad-hoc cleaning, event support, pest control etc), chat to Nimbus staff and managers, and pay their invoices.
HQ
"HQ" is a web admin interface that allows our team to manage everything and quickly fix any operational problems (when it comes to people, there are always problems). This includes reassigning workers each day, seeing an overview of the schedule for the month, seeing who is late, and all the usual account set up.
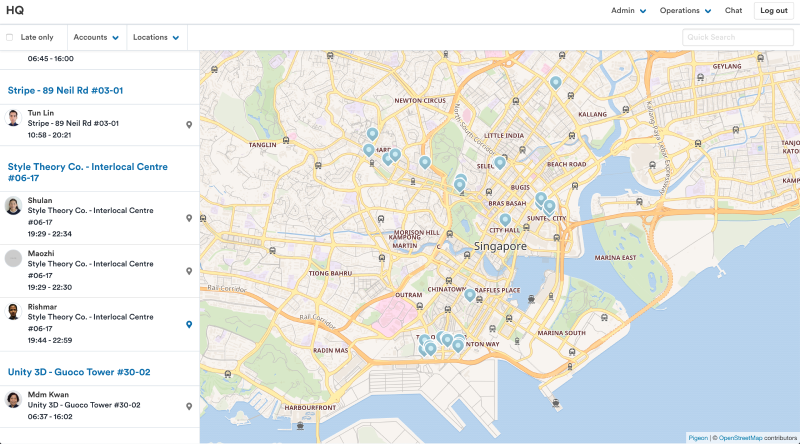 "HQ", our internal admin interface
"HQ", our internal admin interface
Decision framework
Before detailing the tech stack it's worth pointing out the guiding principle I used (and continue to use) in the decision making process. The overarching goal is this:
Reduce the number of developers we need to hire.
In the past I've fallen for the "hire fast, fire fast" mentality and it didn't serve me well. It's bad for culture and bad for the bottom line.
We have been able to achieve high output with less people through several methods:
- Use as few languages and frameworks as possible (we use JS/Node almost everywhere)
- Minimise the total "surface area" of the tech. This means writing as little code as possible.
- Minimise "meta engineering". Although it has its time and place, a lot of tech time can be wasted on automating everything and chasing 100% code coverage.
Number 2 and 3 are hard to achieve while still maintaining speed and stability. At Nimbus they have been largely satisfied because of the following:
- We use functional programming concepts as much as we can (without going overboard). When Nimbus started we used Phoenix (Elixir). Eventually we decided to build iOS/Android apps which required introducing another language. I chose React Native and started moving our codebase to Javascript. If I was to start again I might use Typescript, but for now I'm happy with es6. The functional approach to writing code has persisted, and even without a functional language we've enjoyed many of the benefits that Functional Programming brings (less bugs).
- Compile time "validation". Our products all have to be built, and in that process they use Prettier to format the code consistently. If the build or the formatter fail, it's soft validation that there is a code error. This means that I haven't been chasing unit tests at all. Instead I use Sentry to capture all errors in Dev and Prod and I patch them immediately (a benefit of React Native is that you can do "over the air" updates to mobile apps without a full App Store deployment).
- Relying heavily on the database. I'll elaborate on this later but our Postgres database is the work horse of our tech stack.
- Using solid and well-tested opensource tools. It's crazy how much free value there is in the tech world and I'm past the stage of reimplementing every cool piece of tech I hear about.
Tech stack
 Nimbus tech stack
Nimbus tech stack
Database
Using Postgres is almost cheating in 2019. It's robust, well supported by tools (which you'll see is important in the next section), works on every major cloud provider, and stores JSON for anytime you need to prototype something like you would using a NoSQL database. It also has a NOTIFY/SUBSCRIBE feature where you can attach listeners to table changes (also important soon).
The Firebase database is my worst decision to be honest. We needed something for our chat that could support all the functionality of whatsapp (especially voice messages). I ruled out a lot of "Chat as a Service" providers because I thought Firebase would give us the flexibility that we required. Unfortunately I used their latest database, Cloud Firestore (their recommendation), and it's simply too slow and too limited (e.g. querying across subcollections). Luckily you can attach serverless functions to Firestore CRUD events so we'll use this to as a way to replicate the data into our Postgres database - eventually removing Firestore completely.
API layer
My favourite piece of opensource software is PostgREST (not to be confused with Postgres). Simply start a server, install PostgREST, point it towards your Postgres database, then never touch it again. This gives you a fully-fledged, well tested, and high performace API. Hell, you can even query foreign relationships in one request, just like you would with GraphQL. Security can be pushed all the way down to the database level, and since Postgres has Row Level Security you end up with a API that's pretty damn good. Much better than any I can build myself.
For anything that requires custom logic, we use Serverless functions (mostly AWS Lambda, written in JS). This is where Serverless really shines - small tasks and fringe cases where it wouldn't make sense to spin up a full server. Our typical use cases are integrations with external providers (e.g. Xero) and building data pipelines.
We have a Phoenix (Elixir) server that is used for anything realtime, as well as our database migrations.
Frontend
Our two mobile apps are built using Expo which is a React Native framework. Our web product is built using NextJs which is a React framework.
Although React and React Native aren't 100% compatible, we have managed a lot of code sharing. Even without full compatibility the biggest win is that they are conceptually the same - our intern is now very good with React Native so I'm comfortable that he can help with our web product too. The same could not be said if I had to hire a Swift developer.
Writing less code
Now comes the interesting part. I have already mentioned some things like compile-time validation to reduce "meta-programming". But that's not where the real time savings are found. There are two areas where they are:
- Git submodules
- Declarative data structures
Git submodules
This one is quite obvious.
We have a git repository called nimbus-expo which is shared across our two React Native apps. This contains all the common Expo UI components.
We have another git repository called nimbus-utils that we share across all of our products. This includes helpers, libraries, and common Javascript code. For example, we use MobX for State Management in all three products, so each product has a shell rootStore.js which imports whichever "substores" it needs from nimbus-utils.
This can only be done because I have foregone any temptation to use other languages. I find that I am often refactoring these submodules to reduce the amount of code in them. If you're going down this path it's important to design your code for reusability - in particular you'll want to study up on both the Actor Model and Dependency Injection to ensure your libraries are largely standalone and decoupled.
Declarative data structures
This was a concept that I got from using PostgREST. I became enamoured with the idea that I could make changes to the database and then get free API updates "out of the box". So I started investigating whether I could do the same with our web product.
PostgREST automatically generates an OpenAPI spec, so my first attempts leveraged this with great success. I combined the spec with react-jsonschema-form to generate fully-validated forms which could create and update our database via PostgREST.
There were a few limitations with displaying and ordering of the fields so I recently forked and improved a library which will allow me to inspect our database and create a more robust JSON Schema. It's still early days, however we are moving towards a product that utilises the following developer workflow:
- Change the DB: Make changes to the database. The API is automatically updated because of PostgREST
- Create a JSON Schema: Run a script which inspects the database schema and dumps it as valid JSON Schema
- Create an enrichment schema: Define any layout customisations using an enrichment schema
- Deploy the schemas: Push the new schemas to Prod and the UI is updated automatically
As an added bonus, our products are all kept in sync in realtime. To achieve this, whenever data changes in the database, Postgres creates a NOTIFY event for any insert/update. Our Phoenix server listens to the changes and "shouts" the updates to anyone connected to it via websockets.
Our data flow looks like this:
User AandUser Blog into HQ. This loads all initial data into the MobX storeUser Aupdates a row in the database by sending a PUT request to PostgREST- Postgres notifies our Phoenix server
- The Phoenix server notifies everyone who is logged into HQ
- HQ updates the MobX store
- Everyone sees the same, fresh data with minimal risk of overwriting new changes with old data or race conditions (once again reducing programming effort).

We don't have any conflict resolution when users are editing the same row at the same time, but it's a fringe case that doesn't warrant engineering time.
This whole setup isn't too different that something like Django Admin (which I really like). In this case our "ORM" (the schema) is decoupled from the framework so we can create some very customised pages when we need to.
Worthy mentions
There are a few tools and practices that I have left out for the sake of simplicity but they are worth mentioning to wrap up:
- Queues: we use Bull for our long-running tasks (sending push notifications, emails etc). This is on a small NodeJS server that listens to changes in Postgres and Firebase and then enqueues any long-running tasks.
- We use Feature flags to push code into production for a small subset of users before releasing to everyone. This is another reason why I've been OK with low code coverage so far since we can spot bugs that are occuring and fix them before releasing to everyone.
- We deploy mostly to Elastic Beanstalk which has versioning. If anything fails you can roll back to a previous version. All of our deploys are scripted (eg
npm run deploy) to ensure a fast feedback loop and a speedy patch when things go wrong. - Kanban: we have switched to full kanban rather than sprints/scrums. We still do weekly planning, presentation, and curation but there isn't a stressful "final push" to meet deadlines or an "early lull" as we build up the motivation to tackle a sprint. Kanban feels much more consistent and smooth.
- We will be writing tests over the next few months. Some tests. Not too many. Mostly integration.